Designing a Database for an Online Job Portal
Across the globe, the job portal site is a well-known feature of the Internet landscape. Big players like Indeed and Monster have turned job hunting and recruiting into a veritable online industry. Let’s dive into the elementary features leveraged by job portals and build a data model that can support them.
People love saving time by using technological innovations; the online job portal is another version of working smarter, not harder. Job seekers and companies alike realize the value in taking their search online: they get a better reach at higher speeds and lower costs.
The job portal industry is quite stabilized now, at least in respect to traffic volumes. Job hunters are using these portals to find positions in many industries, moving beyond IT to sectors like engineering, sales, manufacturing, and financial services. However, they are getting tough competition from social media and professional networking sites like LinkedIn. But there are still opportunities to explore, such as expanding their penetration to rural areas and smaller cities.
So as we said, we’re going to explore this topic from a database design perspective. Let’s start with enumerating the fundamental expectations for a job portal.
What Do People Expect From an Online Job Portal?
Both employers and job seekers expect the following functionalities from an online job site:
- People can register as job seekers, build their profiles, and look for jobs matching their skill sets.
- Users can upload their existing resumes. If they do not have one, they should be able to fill out a form and have a resume built for them. In addition, they should have access to a library of resume examples for reference and inspiration.
- People can apply directly to posted jobs.
- Companies can register, post jobs, and search job seeker profiles.
- Multiple representatives from a company should be able to register and post jobs.
- Company representatives can view a list of job applicants and can contact them, initiative an interview, or perform some other action related to their post.
- Registered users should be able to search for jobs and filter the results based on location, required skills, salary, experience level, etc.
Building the Data Model
After considering the above requirements, I came up with three broad functional categories:
- Managing Users – How the portal manages users, i.e. job seekers, HR personnel, and independent or consulting recruiters. (For the purpose of this model, individual HR representatives and independent or consulting recruiters are treated as companies, at least in terms of how they use the portal.)
- Building Profiles – How the portal allows job seekers and organizations to create profiles and resumes.
- Posting and Looking Up Jobs – How the portal facilitates the process of posting, searching, and applying for jobs.
Let’s look at each of these areas separately.
1. Managing Users
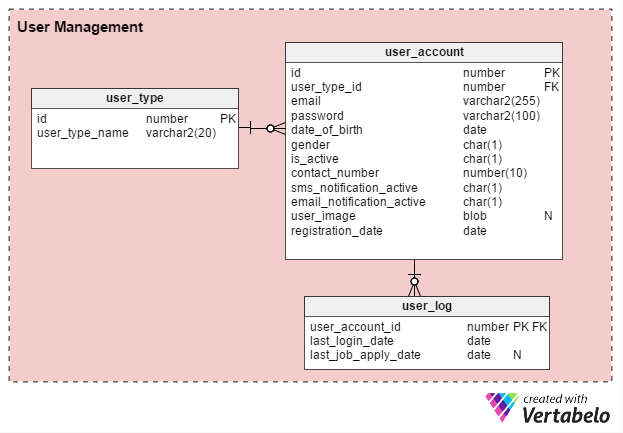
There are primarily two types of online job portal users: individual job seekers and HR recruiters (or independent recruitment consultants). Let’s create a table named user_type to store these records. To start, it will have two records – one for job seekers and another for recruiters. (We can always create additional record types as needed.)
Users are required to register before they can use the portal. The user_account table stores their basic account details. I earlier considered naming this table “user”, but since user is a system-defined keyword in almost all databases, I prefer to stick with “user_account”.
The user_account table has the following columns:
- id – This is both the table’s primary key and a unique identifier for each user. This ID will be referred to by other tables in the data model.
- user_type_id – This signifies whether the user is a job seeker or a recruiter.
- email – This column holds the user’s email address. It acts as another user ID for the portal.
- password – This stores an encrypted account password (created by users during registration).
- date_of_birth and gender – As their names suggest, these columns hold users’ date of birth and gender.
- is_active – Initially this column would be “Y”, but users can set their profile to inactive, or “N”. This column stores their choice.
- contact_number – This is the phone number (usually mobile) provided during registration. Users can receive SMS (text) notifications on this number. It can be the same number (or not) as the one job seekers list in their profile or resume.
- sms_notification_active and email_notification_active – These columns store users’ preferences regarding receiving notifications through text and/or email.
- user_image – This is a BLOB-type attribute that stores each user’s profile image. Since this portal allows only one profile image per user, it makes sense to store it here.
- registration_date – This column keeps a record of when the user registered with the portal.
We’ll create one more table, user_log , that stores a record of users’ last login date and their last job application date. There are a lot of features which can be built from this knowledge. For example, we can use this information to answer the question Is user X actively looking for a job? If so, they can be offered a product for creating an effective resume. Users who aren’t actively looking for a job would not receive such an offer.
2. Building Profiles
We can further divide this section into two areas: company or organizational profiles, and job seeker profiles.
Company Profiles
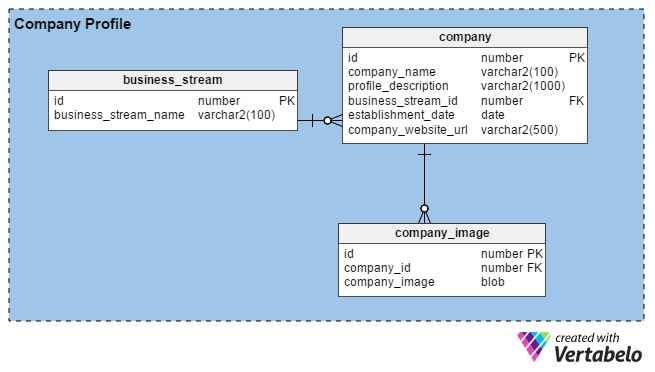
Usually HR teams build company profiles by entering details about their organization and images of their offices, buildings, etc. Their main objective is to attract good talent. When recruiters register with the portal, they too can build profiles of their companies (or their personal brand, if they are independent) by providing some basic details like how long they’ve been in business, their location, and their main business stream (e.g. manufacturing, IT services, financial, etc).
The portal allows HR and consulting recruiters to upload as many images as they like (as opposed to job seekers, who can only upload one). Therefore, we’ve created the company_image table to store multiple images for each recruiter account. The company_id column in this table is a foreign key that refers to the unique identifier used in the company table.
In the company table, we have the following columns:
- id – The primary key of this table is also used to uniquely identify companies.
- company_name – As the column name suggests, this holds the legal name of a company.
- profile_description – This contains a brief description of each company.
- business_stream_id – This column depicts which business stream a company belongs to. For an example, an oil and gas exploration company can hire IT engineers , but their main business stream remains “Oil and Gas”.
- establishment_date – This column tells you how old a company is.
- company_website_url – This is a mandatory (non-nullable) column. It holds a pointer to company’s official website so job seekers can find out more information.
Finally, the business_stream table has just two attributes, an id that is the primary key for this table, and a description of the company’s main business stream (business_stream_name).
Job Seeker Profiles
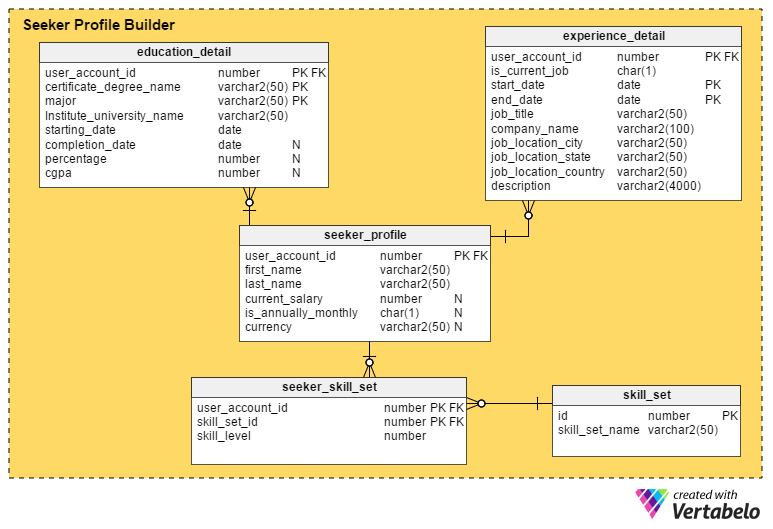
This is the most critical section of a job portal. Unless a portal captures as many details as possible from job seekers, it is difficult for recruiters to shortlist the profiles or candidates.
The seeker_profile table holds additional details that were not captured during the registration process. It contains these fields:
- user_account_id – This column is referred from the user_account table, and it acts as the primary key for this table. It ensures there will be a maximum of one profile per job seeker.
- first_name and last_name – As the names suggest, these columns hold the job seeker’s first and last names.
- current_salary – This attribute contains the job seeker’s current salary. It is nullable because people may not want to disclose it.
- is_annually_monthly – This defines whether their salary amount is per year or per month.
- currency – This stores the currency of the salary.
The education_detail table stores each job seeker’s educational history, as provided by them. It has a composite primary key made up of the user_account_id, certificate_degree_name and major columns. This ensures that users enter only one record for each degree or certificate. The table contains these attributes:
- user_account_id – This column is referred from the user_account table and serves as the primary key for this table.
- certificate_degree_name – This is the certificate or degree type; e.g. high school, higher secondary, graduate, post graduate, or professional certificate.
- major – This column holds the main course of study for the certificate or degree – e.g. a bachelor’s degree with a major in computer science.
- institute_university_name – This is the institute, school, or university that awarded the degree or certificate.
- start_date – This attribute stores the date when the user was accepted into an educational program.
- completion_date – This is the date the degree or certificate was awarded. However, this attribute is nullable; people may still be completing their program while they are looking for a job, or they may have dropped out of the program altogether.
- percentage and cgpa – These columns store the grade percentage or CGPA (cumulative grade point average) attained by users in their degree or certificate course.
The experience_detail table keeps records of users’ past and current professional experience. It contains the following important columns:
- user_account_id – This column is referred from the user_account table and is the primary key for this table.
- is_current_job – This is an indicator column that signifies the user’s current job. This column also plays a major role in deriving users’ current locations and how long they’ve held their current position.
- start_date – This stores when a user starts a job.
- end_date – This stores when a user ends a job.
- job_title – This holds information about the user’s job role.
- company_name – This attributes holds the relevant company name associated with a job.
- job_location_city – This signifies the city where the job was located.
- job_location_state – This signifies the state where the job was located.
- job_location_country – This signifies the country where the job was located.
- description – This column stores details about job roles and responsibilities, challenges, and achievements.
Job seekers can possess multiple skills. To keep records of all of these skill sets, we’ll create the table seeker_skill_set . The columns are:
- user_account_id – This column is referred from the user_account table and is the primary key for this table.
- skill_set_id – This ID signifies which skill set the user possesses.
- skill_level – This numeric attribute quantifies job seekers’ expertise in a particular skill. A number from 1 (beginner) to 10 (expert) indicates their experience level.
Finally, the skill_set table contains descriptions of all the skills referred to in the above table’s skill_set_id attribute. It contains only two columns, a skill_set_name and its related id.
3. Posting and Looking Up Jobs
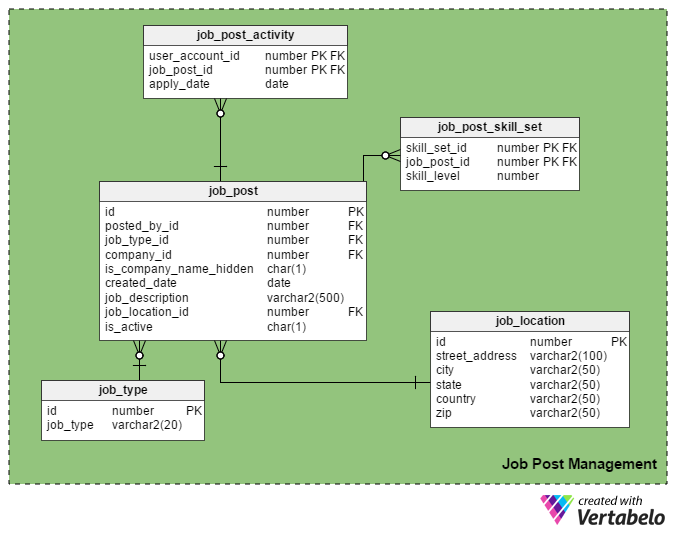
This is the main USP (Unique Selling Point) of a job portal. Only registered recruiters are allowed to post a job on the portal and only registered job seekers are allowed to apply to them.
The job_post table is the main table in this subject area. As you might guess, it holds details about job posts. All the other tables in this section are created around it and linked with it.
- id – This is the primary key of this table. Each job post is assigned a unique number, and this number is referred to in other tables.
- posted_by_id – This column holds the register_user_id of the recruiter who has posted the job.
- job_type_id – This column signifies whether the job duration is permanent or temporary (contract).
- company_id – This column stores the ID of the company related to the job post. It is a reference to the company table.
- is_company_name_hidden – This is a flag column that shows if the company’s name should be shown to job seekers. Recruiters may prefer not to show company names on their post. Instead they use terms like ‘Global Automobile Company’, ‘California-Based IT Company’, and so on.
- created_date – This stores the date when the job is posted.
- job_description – This holds a brief description of the job.
- job_location_id – This refers to an attribute in the job_location table that stores the actual location of the job: street address, city, state, country, and postal code.
- is_active – This signifies if a job is still open. Recruiters can mark their posts inactive as soon as the positions are filled.
The job_post_skill_set table stores details about the skill sets required for a job. The table structure is identical to the seeker_skill_set table.
And the last table in this section, the job_post_activity table, holds details about which job seekers apply for a job and when.
What Would You Add to this Online Job Portal Data Model?
Today’s online job portals do more than provide a platform to post and apply for jobs. They often include other professional services like:
- A personal dashboard to keep a track of job applications
- Real-time updates on applications
- Video resume builders
- Expert resume-writing services
- LinkedIn or other social media profile builders
- Salary reports across job roles, companies, industries, or geographical locations
If we wanted to build these features into our system, what additional changes would we need to make? Can you think of any other must-haves in a job portal?
Please let us know your views in the comments section.
Subscribe to our newsletter Join our weekly newsletter to be notified about the latest posts. Subscribe
